I’ve been musing a bit lately about the problem of having too much information on our computer screens to deal with. I’ve also been thinking about the problems involved in using a computer as the hub of an entertainment center. What follows is a concept that might be able to address both problems, as well as a few others.
This is a gadget I call the “sidepad.†It has a few modes of operation.
1. Docked mode
In this mode, the sidepad is physically connected (via a docking station) to the host computer, and acts as a specialized secondary display.
I’ve written before that I like the idea of roping off a section of my display for to use as for status-monitoring displays and the like, or better yet, a separate display entirely. There wouldn’t be enough of this ancillary stuff to fill a normal display (even a small one), but a custom display such as I am proposing would be perfect.
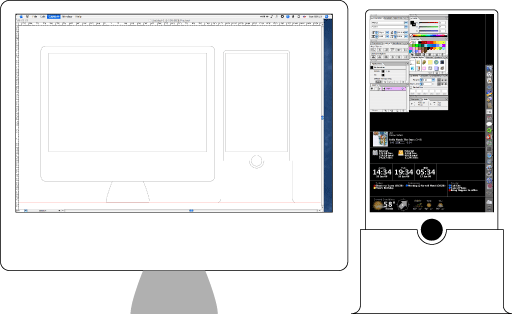
Shown here is a very rough mockup of a 20“ iMac with an ancillary display showing how the two would relate.
Here is a detail of just the sidepad in docked mode
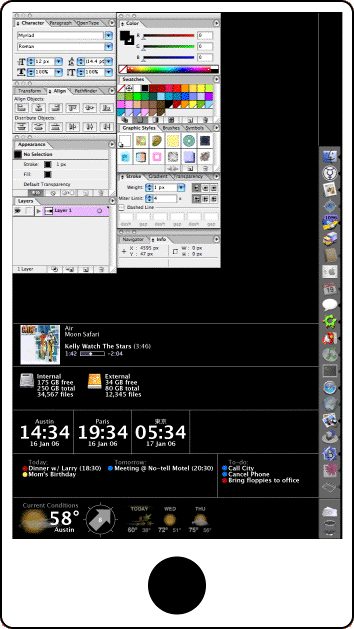
In this, the ancillary display shows the dock, application palettes, and â€dashboard“-style information, though in a much simpler and more disciplined format than Apple’s Dashboard. For lack of a better name, I’ll tentatively call this part of the display the â€dashpad“. Rather than having each widget being free-floating and self-contained, each dashpad widget fits into a â€slot“ and has no chrome (though actual widgets in this case could be somewhat dressier than I am showing them here). I have left the application palettes alone, although I envision a standard visual format for them, along with a special API to take advantage of the ancillary display.
How would something like this work technically? At the physical level, I imagine a dock that would connect to the host via Firewire. Although it would act in some respects as a second display, it would probably need to be treated more as a peripheral; it would have its own processor, which would need to collaborate with the host to fake acting like a second display in some respects.
At the software level, the OS would need a new API that let applications relegate palette display to the sidepad when present, along with support in the OS for the look and actions of those palettes. Likewise display of the dashpad.
2. Detached mode
In this mode, the sidepad is undocked from the host computer, but within wifi range, and acts as a remote terminal for that computer, as well as the command center for home entertainment.
We’re at a point where having a remote display for one’s home computer can be incredibly handy. Such as:
- You see something while watching TV and want to check some background info on the web (IMDB entry on an actor, product website for something you see advertised).
- You are piping music from your computer to your stereo. You want to be able to see track info, and to have more control over playback than next/previous track buttons on a normal remote offer.
Obviously these tasks can be accomplished with another computer networked into your primary computer, but this can require a fair amount of setup, and the expense and maintenance of an another computer. Apple likes to talk about its computers being â€digital hubs,“ and I love the idea, but I need to be able to use it out at the ends of the spokes.
Shown here is the sidepad removed from the dock. It would communicate with the host over wifi (probably setting up a VPN). Assuming the mac was also hooked up to, say, a TV and stereo, the sidepad would work as a remote control in this mode, directing media signals to the appropriate outputs.
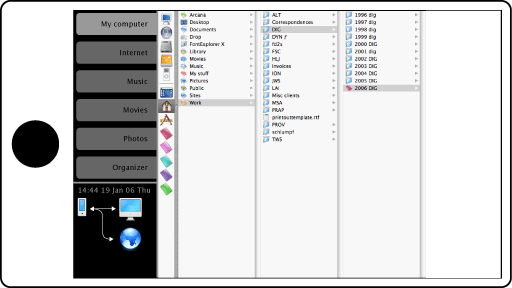
In this mode, the screen would show something completely different. A fixed source browser would appear on the top-left, with tabs for one’s computer, the Internet (which would show a browser in the remainder of the screen), music, movies, photos (which would hook into the appropriate sources on the host’s hard drive, and display suitable browsers), and an organizer (contacts and calendar that would sync with the appropriate iApps).
3. Outbound mode
In this mode, the sidepad is operating independently of the host computer, functioning as an Internet terminal, media player, and PDA.
A lot of people who mostly need a desktop computer could also use something lightweight for e-mail, web surfing, and entertainment when they are away from home. The proportions of the display are not an accident: it has a 16×10 aspect ratio, for widescreen video. A laptop (especially a used one) is not an unreasonable solution, but may be overkill, and requires more work (and if Apple has its way, a .Mac subscription) to keep in sync with one’s desktop. Low-powered, small, and lightweight web-surfing tablets such as the Nokia 770 and Pepperpad already exist, but these are not really designed to sync with larger computers, much less provide either of the other modes I’ve discussed.
In order to fulfill its other functions, the sidepad would need a powerful enough processor to act as a PDA, with utility applications like a word processor, spreadsheet, and e-book reader. So it would be a no-brainer to include these functions in this mode.
One aspect of this mode that is open to criticism is the fact that it would require a fair amount of storage to be useful, increasing its price and putting it dangerously close to iPod territory. This could be handled by making storage optional, by using a memory-card slot, or by actually designing in an iPod dock.
The display in this mode would be very similar to that in Detached mode. The functionality would be different, though. The â€my computer“ tab might be disabled if a VPN at a decent speed cannot be established. The media tabs would reveal locally stored content, not content on the host computer.
Objections
What are the odds of something like this being built? Slim. There are a lot of problems with this idea:
- Price: it might wind up being expensive enough that most people would reasonably ask â€why not just get a laptop?“
- Size: For one thing, the size is not one we’ve seen before in a portable product—bigger than a PDA, PMP, or portable game console, but smaller than a laptop. The fact that nobody’s selling a device this size (measuring roughly 12†x 6“, the size of a license plate in North America) may be because nobody would buy it. For another thing, in order to feel well-connected to the host machine in docked mode might require different models for different screen sizes.
- Marketing: With several different modes, none of which are ones that most consumers will instantly grok, this would be a challenge to sell effectively.
Still, I’d buy one.