I don’t expect to do a lot of Japanese text entry on my iPhone, but I’m glad that I have the option, and I’ve been enjoying playing around with that feature.
Any Japanese text-entry function is necessarily more complex than an English one. In English, we pretty much have a one-to-one mapping between the key struck and the letter produced. Occasionally we need to insert åçcéñted characters, but the additional work is minimal. In Japanese, the most common method of input on computers is to type phonetically on a QWERTY keyboard, which produces syllabic characters (hiragana) on-screen—type k-u to get the kana ã, which is pronounced ku; after you’ve typed in a phrase or sentence, you hit the “convert” key (normally the space bar), and software guesses what kanji you might want to use, based on straight dictionary equivalents, your historical input, and some grammar parsing. So for the Japanese for “International,” you would type k-o-k-u-s-a-i; initially this would appear on-screen as ã“ãã•ã„, and then after hitting the convert key, you would see 国際 as an option. Now, that’s not the only word in Japanese with that pronunciation—the word for “government bond” sounds exactly the same and would be typed the same on a keyboard. To access that, you’d go through the same process, and after 国際 appeared on-screen, you’d hit the convert key again to get its next guess, which would be 国債, the correct pair of kanji. Sometimes there will be more candidates, in which case a floating menu will appear on-screen.
The first exposure most English speakers have had to the problem of producing more characters than your input device has keys has come with cellphones. T9 input on keypad is a good analogue to Japanese input on QWERTY: you type keys that each represent three letters, and when you hit the space key, T9 looks up the words you might have meant, showing a floating menu.
The iPhone, of course, uses a virtual QWERTY keyboard for English input, which is pretty good, especially considering the lack of tactile feedback and tiny keys. It guesses what word you might be trying to type based on adjacent keys. It does not (as far as I can tell) give multiple options, and isn’t very aggressive about suggesting finished words based on incomplete words. For English, at least, I’m guessing Apple decided that multiple candidates for a given input are too confusing. In general, the trend for heavy English text input on mobile devices seems to be towards small QWERTY keyboards, despite the facility some people have with T9. I’m wondering how many people are put off by the multiple-candidate aspect of T9, and if that’s why Apple omitted that aspect, or if it’s simply that not enough English-speakers are accustomed to dealing with multiple candidates.
Japanese input on the iPhone is different. It is aggressive about suggesting complete words and phrases. It does show multiple options (which is necessary in Japanese, and which Japanese users are accustomed to). In fact, it suggests kanji-converted phrases based on incomplete, incorrect kana input. Here’s an example based on the above:
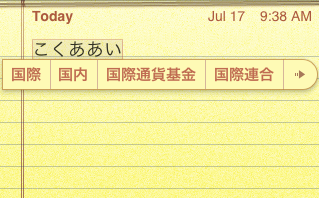
Here, I typed k-o-k-u-a-a-i (note the intentional typo), which appears as ã“ãã‚ã‚ã„. It shows a bunch of candidates, including the corrected and converted 国際, a logical alternative 国内, and some much longer ones, like 国際通貨基金—the International Monetary Fund. Since it has more candidates than it has room to display, it shows a little → which takes you to an expanded candidates screen. Just for grins, I will accept 国際通貨基金 as my preferred candidate. Here’s another neat predictive trick: immediately after I select that candidate, it shows sentence-particle candidates like ã« ãŒ, etc.
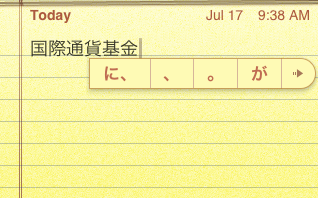
Let’s follow that arrow and see what other options it shows:

I’m going to select ã‚’ as my candidate. It immediately shows some verbs as candidates:
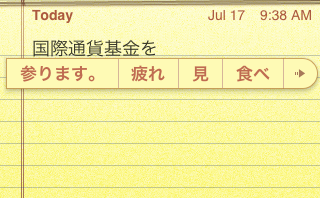
Here, å‚ã‚Šã¾ã™ is a verb I used previously, but 見 and 食㹠are just common verbs—I’m guessing they’ve been weighted by the input function as likely for use in text messages (the phrase 国際通貨基金を食㹠is somewhat unlikely in real life, unless you are Godzilla).
The iPhone also has an interesting kana-input mode, which uses an ã‚ã‹ã•ãŸãª grid with pie menus under each letter for the rest of the vowel-row. It looks like this:
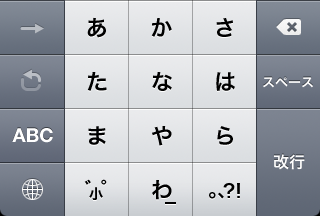
To enter an -a character, just tap it:

To enter a character from a different vowel-line, slide your finger in the appropriate direction on the pie-menu that appears and release:
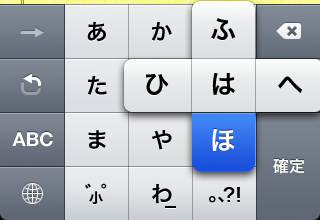
You can also get at characters from a different vowel-line using that hooked arrow, which iterates through them. I haven’t figured out what that forward arrow is for. It’s usually disabled, and only enabled momentarily after tapping in a new character. Tapping it doesn’t seem to have any effect.
This method offers the same error-forgiveness and predictive power as Japanese via QWERTY. I don’t find it to be faster than QWERTY though, but perhaps that’s just because I’m not used to it.
One thing I haven’t found is a way to edit the text-expansion dictionary directly. This would be very handy. I’m sure there are a few more tricks in store.
Also, a fun trick you can use on your Mac well as on an iPhone to get at special symbols: enter ゆー゠to get €. Same with ã½ã‚“ã©ã€ã‚„ã˜ã‚‹ã—ã€ã‚†ã†ã³ã‚“, etc.
Update Apparently the mysterious forward-arrow breaks you out of iterating through the options under one key, as explained here. Normally if you press ã‚ ã‚, this would iterate through that vowel-line, and produce ã„. But if you actually want to produce ã‚ã‚, you would type ã‚→゠(Thanks, Manako).

 iTunes is overloaded.
iTunes is overloaded.
